
Datendimensionen im Data Lakehousing - SCD und RCD
Tauche ein in die Welt der Datendimensionen im Data Lakehouse und erfahre, wie verschiedene SCD- und RCD-Strategien die Historisierung und Konsistenz deiner Daten verbessern. Der Artikel erklärt die wichtigsten Typen, ihre Anwendung und gibt praxisnahe Tipps für eine effiziente Datenarchitektur.
Datendimensionen im Data Lakehousing - SCD und RCD
Die Einhaltung eines einheitliches Data Warehousing Konzeptes ist wichtig für eine funktionierende Datenstrategie. Sehr häufig wird dabei ein Star-Schema verwendet. Das bedeutet, dass Daten in Fakten und Dimensionen unterteilt werden.
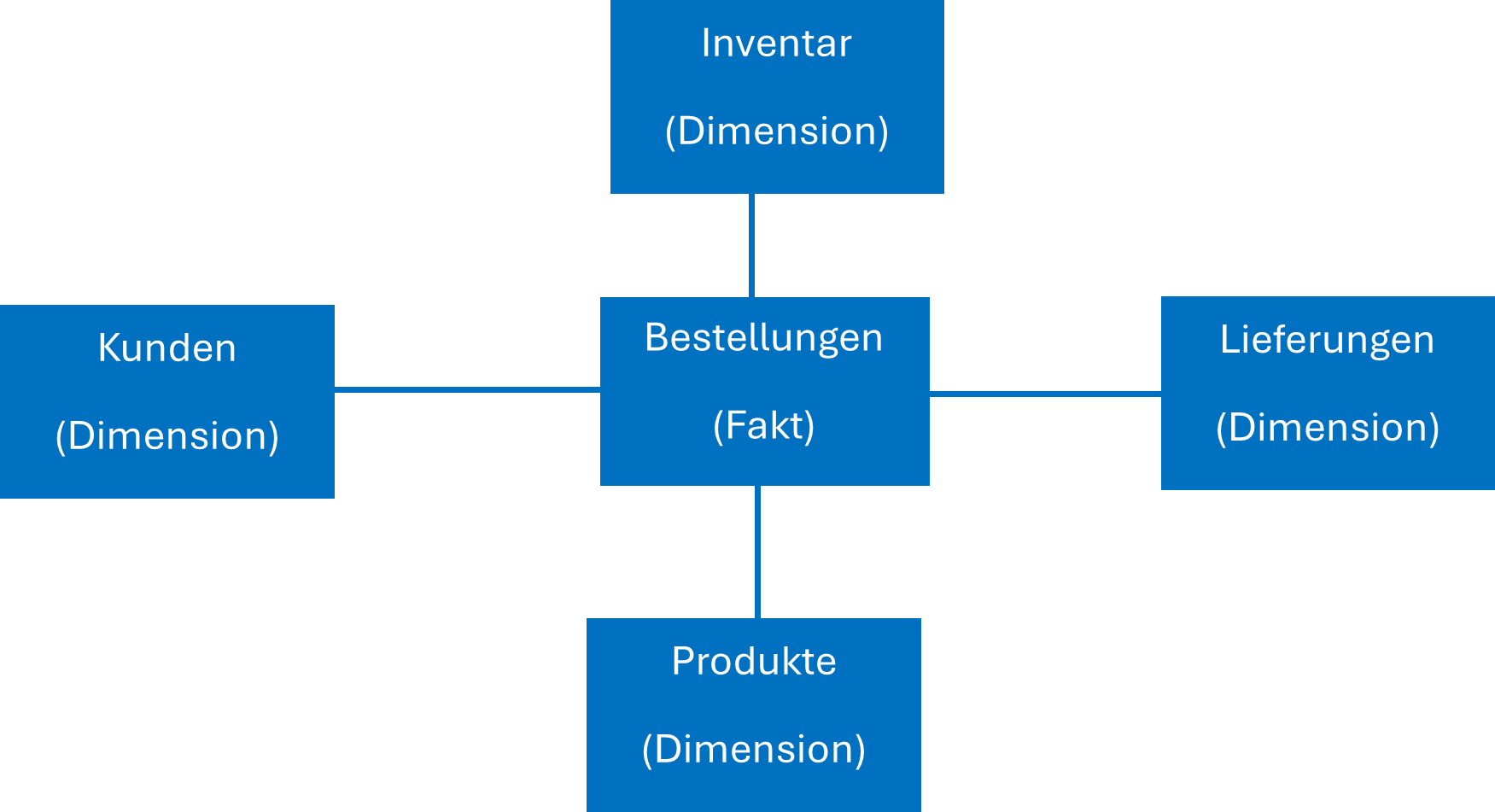
Das Star Schema
Man spricht von einem Star Schema, weil in Darstellungen die Fakten häufig in der Mitte stehen und mit den Dimensionen außen herum einen Stern bilden. Mit Dimensionen sind hier alle qualitativen Daten oder beschreibende Attribute gemeint, die den Kontext für die Fakten liefern. Die Fakten liefern dann Daten über Business Prozesse und Events.
Ein gängiges Beispiel ist hierbei ein Onlineshop. Dieser hat Produkte, Kunden, Lieferdaten und Inventar. Diese Dimensionen werden mit den Bestellungen als Faktentabelle verknüpft. Diese enthält dabei in der Regel keine weiteren Informationen und gibt nur über den tatsächlichen Einkaufsprozess Auskunft - komplett ohne Daten zu Produkten, Kunden usw.
Die Daten sind also komplett denormalisiert. Das erzeugt einen enormen Performance Boost für Reporting Abfragen. Dieses Konzept steht damit in Kontrast zu einem Flat Table Schema, bei dem die zusammenhängenden Daten einfach in einer großen Tabelle gespeichert werden.
Das Problem des Star Schemas
Während das Star-Schema einen großen Vorteil in der Performance von Abfragen mitbringt, hat es ein großes Problem mit Datenkonsistenz.
Würde ein Kunde in unserem obigen Beispiel seine Adresse Ändern, wäre diese für alle vorherigen Bestellungen auch geändert, da die Bestellung auf dieselbe Kundennummer verweist.
Das ist ein Albtraum für Revisionssicherheit und Datenanalysen von historischen Daten. Genau hier setzen verschiedene Methoden für Slowly Changing Dimensions (SCD) an. Sie sorgen dafür, dass unsere Daten versioniert werden und für jede Zeile in unserer Faktentabelle stets ein Element mit korrekten in den Dimensionstabellen vorliegt.
Als zusätzlichen Bonus werden diese Daten Data Engineers und Data Analysts nicht nur dabei helfen, die Faktentabellen zu füllen, sondern bieten auch wertvolle Insights in die Dimensionsdaten selbst. Es können Auswertungen über Inventarbestände oder auch Kundenverhalten durchgeführt werden.
Slowly-/ Rapid Changing Dimensions
In unserem Beispiel mit der Kundenadresse haben wir gesehen, dass sich unsere Dimenstabellen (In diesem Fall die Kundentabelle) ändern. Änderungen an den Kundenstammdaten sind eher selten - hier sprechen wir von Slowly Changing Dimensions.
Es gibt allerdings auch Dimensionen die sich sehr häufig Ändern. Bei unserem Onlineshop z.B. das Produktinventar. Man spricht von Rapid Changing Dimensions - sie haben einen deutlich höheren Speicherbedarf und können in der Versionierung einen negativen Einfluss auf die Performance unseres Data Lakehouses haben.
Wir werden uns im nächsten Schritt die Verschiedenen Typen zur Versionierung ansehen. Diese sind allgemein mit SCD 0 bis SCD 6 benannt. Je nach Lektüre findet man auch nur SCD 0 bis SCD 3. Diese Versionierungs Typen können natürlich auch für RCDs angewandt werden. Aufgrund ihrer hohen Anzahl an Änderungen muss hier immer abgewägt werden, ob die Vorteile durch Historisierung dieser Daten die Nachteile Nachteile in Performance rechtfertigen.
SCD Typen
Die Versionierung bzw. Historisierung unserer Daten erfolgt mit einem der vier bzw. sieben SCD Typen. Ohne es zu wissen hast Du sicher schon einen dieser verwendet:
- SCD Type 0 „Retain Original": Beim Type 0 sind keine Änderungen zugelassen. Neue Daten werden in die Tabellen geschrieben und alte werden nicht aktualisiert. Dieser Typ ist für Daten die sich grundsätzlich nicht ändern geeignet (z.B. Postleitzahlen).
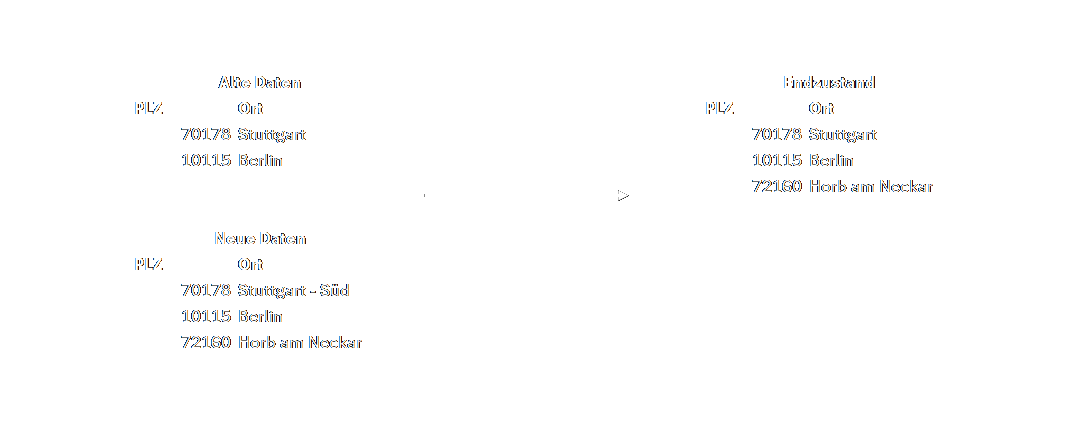
- SCD Type 1 „Overwrite": Das ist meiner Erfahrung nach der Typ der am häufigsten anzutreffen ist. Wie beim Type 0 werden neue Daten der Tabelle angehängt. Werden Daten mit demselben Primärschlüssel ein weiteres Mal hinzugefügt, werden sie überschrieben. Eine Historisierung passiert hier allerdings - wie beim Type 0 - noch nicht.
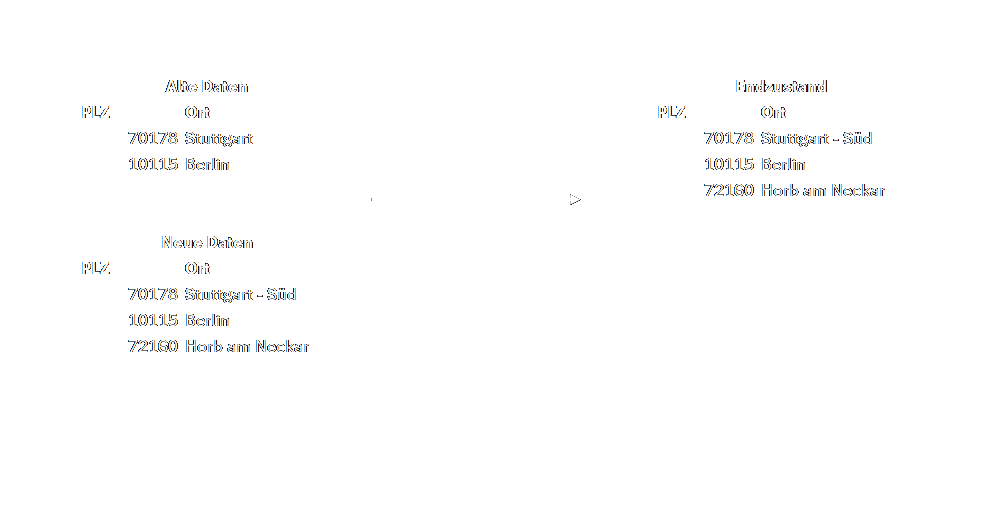
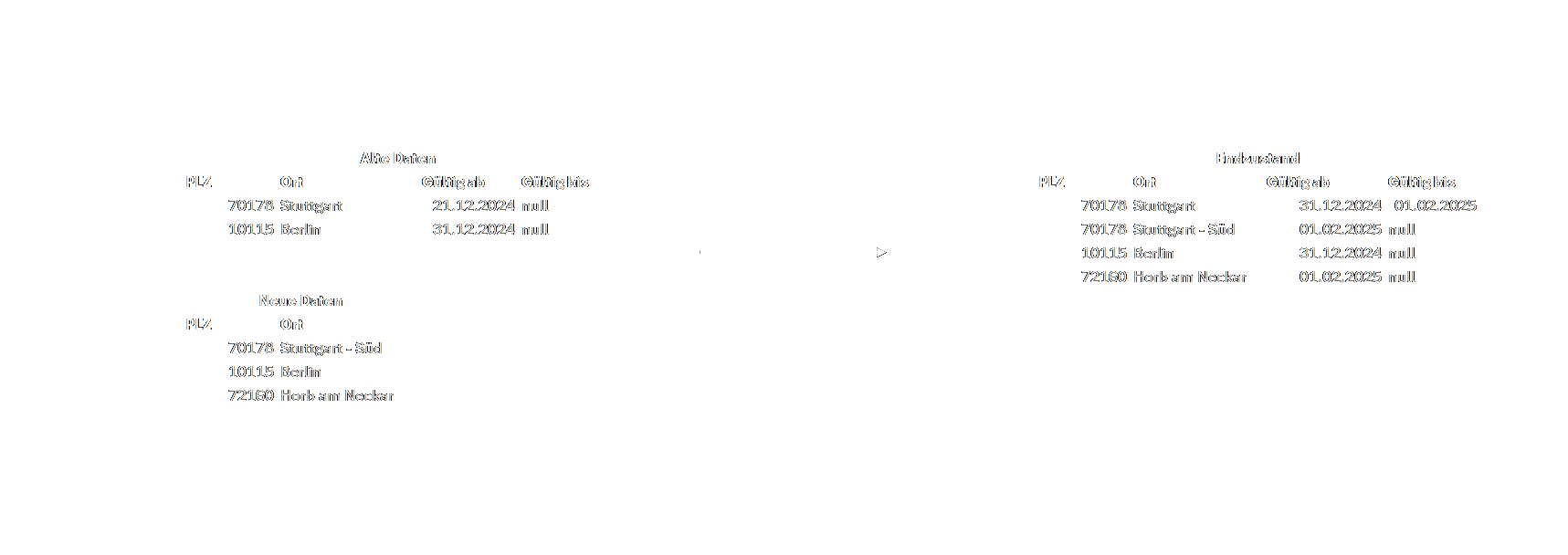
- SCD Type 2 „Add New Row": Der Type 2 funktioniert exakt wie der Type 1. Hier wird allerdings erstmals eine Historisierung eingeführt. Wenn eine neue Zeile mit vorhandenem Primärschlüssel eingefügt wird, wird hier statt die alte Zeile zu überschreiben, eine neue Zeile mit dem neuen Wert angelegt. Dazu werden in der Tabelle „gültig ab" und „gültig bis" Spalten ergänzt. Wird eine vorhandene Zeile also geändert, wird eine neue Zeile wird mit dem aktuellen Datum und Uhrzeit in der „gültig ab" Spalte ergänzt. In der jetzt alte Zeile wird die „gültig bis" Spalte auf das aktuelle Datum und Uhrzeit gesetzt. Auf diese Weise kann für jeden Zeitpunkt eine valide Zeile gefunden werden.
- SCD Type 3 „Add New Attribute": Type 3 fügt statt eines neuen Zeile für eine Änderung ein neues Feld ein. Diese Felder müssen vorher festgelegt werden. So könnte man bspw. die letzten drei Preisänderungen eines Produktes in derselben Zeile tracken. Diese Methode behält keine komplette Versionierung für eine Zeile oder ein Attribut, da die Anzahl an Einträgen bei der Erstellung der Tabelle festgelegt werden muss.

-
SCD Type 4 „Add History Table": Type 4 funktioniert wie Change Data Capture in Datenbanksystemen. In der Dimensionstabelle wird ausschließlich der aktuelle Wert gespeichert. Die Versionierung von alten Daten findet dann in einer zusätzlichen Tabelle statt. Dieser Ansatz eignet sich speziell auch für Tabellen mit sich oft ändernden Daten.
-
SCD Type 5 „Mini Dimension": Type 5 ergänzt Type 4 in der Dimensionstabelle um eine Mini-Dimension. Sich sehr häufig Ändernde Daten können so ausgelagert werden. Eine Referenz zum aktuellen Wert in der Historisierungstabelle wird dann als Fremdschlüssel on der eigentlichen Dimensionstabelle abgespeichert. Diese Methode eignet sich speziell auch für Tabellen mit sich teilweise oft ändernden Daten.
-
SCD Type 6 „Combined Approach": Dieser Ansatz verbindet SCD Type 1, Type 2 und Type 3. Historische und aktuelle Daten können so in derselben Zeile abgespeichert werden. Ein Beispiel in dem Dieser SCD Type Sinn macht, sind Artikelpreise. Wird ein Preis geändert, kann eine neue Zeile angelegt werden und der vorige Preis wird in einer speziellen Spalte gespeichert. Das erleichtert den Zugriff, wenn z.B. ein Rabatt berechnet werden muss.
Bei der Wahl des korrekten SCD Types für Deine Daten solltest Du für Deinen Usecase und Deine Datenarten abwägen, welche Methode Deine Anforderungen im Hinblick auf Historisierungslevel, Zugriffsgeschwindigkeit, Redundanz, Skalierbarkeit, Wartbarkeit und natürlich Speicherbedarf genügt.