
DIY - Effiziente Datenreplikation von Datenbanken im Data Lakehouse
Lerne, wie du Datenbanken effizient und kostengünstig in dein Data Lakehouse replizierst. Der Artikel zeigt dir verschiedene DIY-Strategien zur Datenreplikation, erklärt Vor- und Nachteile gängiger Methoden und gibt praktische Tipps für die Umsetzung ohne teure ELT-Tools.
DIY - Effiziente Datenreplikation von Datenbanken im Data Lakehouse
Daten Replikation gehört zu den wichtigsten Aufgaben eines Data Engineer. Daten müssen effizient aus den Quellsystemen geladen werden. Am besten, ohne dass davon irgendjemand etwas mitbekommt.
Das ist einfacher als es klingt! Viele Systeme sind riesig, alt oder beides. Oft müssen Diskussionen mit Verantwortlichen geführt werden. Es gilt einen breiten Schatz an Werkzeugen aufzubauen, um für jedes Problem das richtige zu haben. Hier versprechen einige Tools schnelle und einfache Abhilfe - Quasi den Hammer, mit dem bekanntlich alles repariert werden kann.
Und das funktioniert anfangs auch meistens relativ gut. Allerdings hat das alles einen Preis - und der ist hoch! Das schlimmste, das ich in meiner jungen Karriere als Data Engineer sehen durfte, waren Rechnungen von Fivetran bzw. anderen ELT-Tools. Ich habe von großen Firmen gehört, die deutlich mehr für die Replikationen ihrer Daten ausgeben als für ihr gesamtes Data Lakehouse.
Was diese Tools machen, ist aber grundsätzlich mit etwas technischem Verständnis keine Magie und mit einigen Stunden Arbeit lässt sich so gut wie jede Datenquelle unkompliziert integrieren.
Damit auch Du in Zukunft kosteneffizient Daten in Dein Lakehouse bringst, ohne die Produktionsdatenbank zu crashen, schauen wir uns heute einen DIY-Ansatz ohne weitere Tools an.
Replikation bei kleinen Datenbanken
Sehr kleine Datenbanken mit weniger als hundert Tausend Zeilen pro Tabelle, erfordern für gewöhnlich keine aufwändige Replikationsstrategie.
Es macht hierbei Sinn, die Tabellen jedes Mal vollständig abzurufen. Dabei macht es Sinn, Spark jdbc zu verwenden.
Mit
employees_table = (spark.read
.format("jdbc")
.option("url", "<jdbc-url>")
.option("dbtable", "<table-name>")
.option("user", "<username>")
.option("password", "<password>")
.load()
)
Würde die Mitarbeitertabelle der entsprechenden Datenbank in ein Spark Dataframe geschrieben werden. Das beste Dabei: Das Schema wird direkt erkannt und übersetzt - das Dataframe kann faktisch direkt in eine Databricks Delta-Tabelle geschrieben werden.
Zu beachten ist einzig, dass der korrekte Treiber installiert wird. Während Microsoft SQL vorinstalliert ist, fehlen Databricks Treiber für bspw. Oracle Datenbanken.
Zum Speichern der Daten im Data Lake kann anschließend entweder die ganze Tabelle überschrieben werden (sehr aufwändig und rechenintensiv), oder ein Merge angewandt werden. Letzteres funktioniert allerdings nur, wenn die Primärschlüssel der Tabellen bekannt sind.
Replikation bei großen Datenbanken
Während sich die Anbindung von sehr kleinen Datenbanken sehr einfach darstellt, muss bei größeren Datenbanken eine Replikationsstrategie gewählt werden.
Hier gibt es leider keinen „one-size-fits-all" und für und wider müssen jedes Mal aufs neue abgewogen werden. Im schlimmsten Fall müssen sogar pro Datenbank mehrere Stategien auf ein Mal gefahren werden.
Man unterscheidet unter anderem folgende Methoden:
Vollabzug
Diese Methode haben wir gerade kennengelernt. Dabei wird jede Tabelle einfach bei jedem Replikationsschritt komplett abgerufen. Sie ist sehr einfach zu implementieren aber dauert jedes Mal - je nach Größe der Tabelle - relativ lange und verbraucht sehr viele Ressourcen. Sie eignet sich also nur für sehr kleine Tabellen.
Für größere Tabellen bietet Spark allerdings die Möglichkeit, die Tabelle in mehreren kleinen Schritten abzurufen und die Tabelle zu partitionieren. Hierbei können die Optionen „numPartitions", „partitionColumn", „lowerbound" und „upperbound" zu unserem Code weiter oben ergänzt werden. Da die Last auf die Quelldatenbank aber enorm sein kann, rate ich von diesem Weg grundsätzlich eher ab und beleuchte ihn nicht weiter. Für Interessierte findet sich aber hier ein Artikel (Spark Concurrent JDBC Data Reads | Medium).
Inkrementelles Laden mit Change Data Feed
Ein Change Data Feed ist eine Funktion, die die meisten Datenbanken out oft he Box zur Verfügung stellen. Hierbei bietet die Datenbank für alle überwachten Tabellen eine weitere Tabelle an, die die Änderungen nachverfolgt. Ruft man diesen regelmäßig ab, können also die Änderungen in der Zieltabelle nachverfolgt werden. Es werden nur die Daten abgerufen, die sich wirklich geändert haben.
Während diese Methode für sehr große Datenbanken sehr gut funktioniert und nur ein Minimum an Ressourcen verbraucht, muss diese Funktion i.d.R. erst aktiviert werden. Ohne entsprechende Rechte auf der Datenbank ist das nicht möglich.
Wenn die Datenbank von einer Fremdfirma verwaltet wird, gestaltet sich die Änderung ebenfalls als sehr schwierig. Wo möglich sollte diese Methode allerdings angewandt werden.
Inkrementelles Laden mit Zeitstempel
Diese Methode setzt bestimmte Audit-Felder in jeder zu replizierenden Tabelle voraus. Darunter versteht man i.d.R. Zeitstempel für Änderungen bzw. Erstellungen. Viele Datenbanken werden zur Nachvollziehbarkeit von Änderungen mit diesen Feldern ausgestattet.
Mit dem Änderungs- Zeitstempel können Änderungen nach dem letzten Durchlauf unserer Replikation nachvollzogen werden. Auch hier ist die Last auf die Datenbank also sehr gering. Neu erstellte und geänderte Zeilen rutschen jedes Mal nach oben und werden bei Bedarf abgerufen.
Zu beachten ist hier, dass z.T. ein Änderungs- Zeitstempel noch vor dem Commit einer Änderung berechnet werden kann. Das würde bedeuten, dass Zeilen bei der Replikation übersehen werden und nie übertragen werden. Hier muss also ein gewisser Puffer (z.B. von 10 min) bei der Übertragung berücksichtigt werden.
Ein großer Nachteil dieser Methode ist, dass Löschungen nicht abgefangen werden können. In den meisten Produktiven System wird empfohlen, Daten nicht direkt zu löschen (hard deletes), sondern zu markieren (soft deletes) - sofern es dafür keine rechtlichen Anforderungen gibt - um Nachvollziehbarkeit zu gewährleisten. dennoch werden immer noch Systeme mit hard- statt soft deletes gebaut und vertrieben.
Wenn diese zusätzlich berücksichtigt werden sollen, könnte in regelmäßigen Abständen ein Vollabzug der Primärschlüssel erzeugt werden und mit der Zieldatenbank abgeglichen werden. Alternativ lässt sich auch die nächste Methode zum Abruf der Löschungen anwenden.
Beispiel für eine Inkrementelle Query Funktion mit Zeitstempel:
def incementalLoading(cursor_value, table_name):
employees_table = (spark.read
.format("jdbc")
.option("url", "<jdbc-url>")
.option("dbtable", f"(SELECT * FROM {table_name} WHERE last_modified >= {cursor_value})")
.option("user", "<username>")
.option("password", "<password>")
.load()
)
return employees_table
Wir sehen, dass wir der spark.read Funktion auch jede andere Select Query geben können - nicht nur einen Tabellennamen.
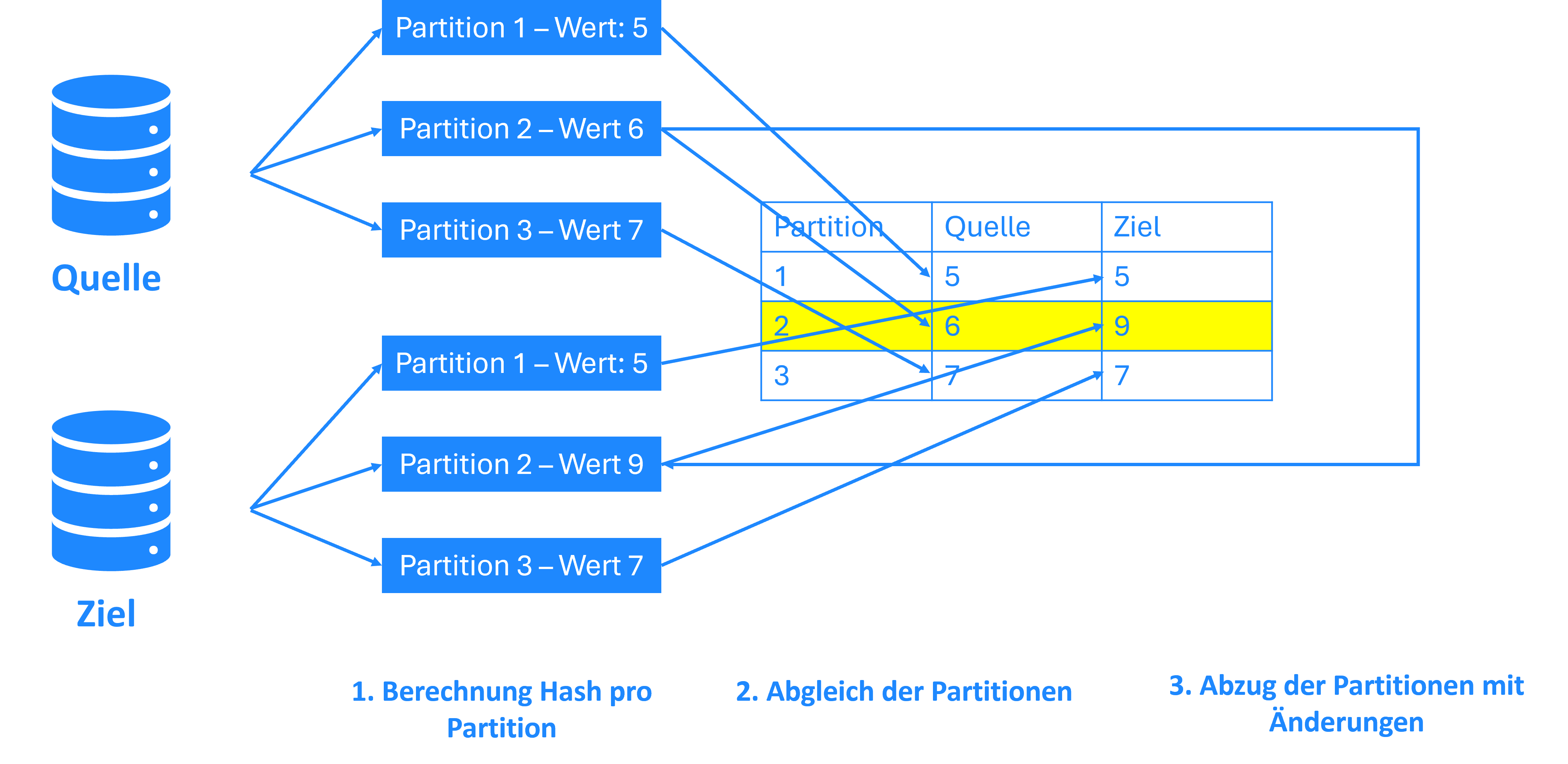
Logische Replikation
Die logische Replikation ist das Aufwändigste hier beschriebene Verfahren. Hierbei werden zuerst die Tabellen in Partitionen eingeteilt (z.B. nach Monat oder einem Inkrementellen Schlüssen). Anschließend werden von beiden Datenbanken (Quelle und Ziel) Rechenoperationen für jede dieser Partitionen durchgeführt. In der Regel wird ein Hash Wert berechnet, der die Daten in einen einzigen Wert für jede Partition zusammenfasst.
Diese Partitionstabellen werden schließlich abgeglichen und nur Partitionen mit Änderungen werden komplett abgerufen.
Diese Methode macht den Umstand zu Nutze, dass sich bei großen Systemen alte Daten normalerweise selten Ändern und neue häufiger. Somit werden auch nur diese Partitionen abgerufen.
Beim Abruf von Löschungen in Kombination mit der Inkrementellen Replikation, können die Zeilen jeder Partition gezählt werden - das verringert die Last auf die Datenbank bei der Berechnung.
Während diese Methode zu den Rechenintensivsten zählt, ist sie sogleich die Vielseitigste. Egal wie die Datenbank aussieht und wie sie aufgebaut ist, kann diese Methode angewandt werden. Sie funktioniert dabei - anders als Vollabzüge - auch für größere Systeme.
Fazit
Grundsätzlich sollte immer die schonendste Form der Replikation angewandt werden, um die produktive Arbeit an den Systemen nicht zu stören. Sollte dies nicht möglich sein, sollte eine aufwändigere Replikationsmethode nur in Zeiten geringer Auslastung verwendet werden (Bspw. nachts).
Eine gute Vorgehensweise ist immer, zu prüfen, ob Änderungen an der Datenbank möglich sind, um CDC einzusetzen. Dann zu prüfen, ob die Datenbank Tabellen Audit Felder aufweist. Wenn das alles nicht zutrifft, sollte Logische Replikation oder ein Vollabzug außerhalb der Nutzungszeiten verwendet werden.
Während den ersten Tagen der Nutzung sollte dabei die Datenbanklast regelmäßig beobachtet werden - egal welche Methode verwendet wird.