
Volle Kostenkontrolle in Azure Databricks – Transparenz und Optimierung
Erfahre, wie du mit gezielten Strategien und Tools die Kosten in Azure Databricks transparent machst und optimierst. Der Artikel zeigt dir, wie du Kostenarten identifizierst, Ausgaben analysierst und durch Best Practices die Effizienz deiner Data Lakehouse-Workloads steigerst.
Volle Kostenkontrolle in Azure Databricks - Transparenz und Optimierung
Wenn man noch nicht viele Berührungspunkte mit Azure Databricks oder der Cloud generell hatte, wirkt diese Thematik u.U. sehr undurchsichtig. Daher möchte ich Dir in diesem Blog Artikel ein paar Einblicke geben, wie Du die volle Kostenkontrolle in Deiner Azure Databricks Umgebung schaffen kannst.
Kostenarten in Azure Databricks
Der Preis, den Du für Azure Databricks bezahlen muss, setzt sich aus drei Typen zusammen, die alle unterschiedlich mit der Datenmenge und den Aufwänden in den Datenpipelines skalieren.
- Cloud Ressourcen: Databricks greift für den Betrieb auf Ressourcen von Hyperscalern in den Subscriptions der Kunden selbst zurück. Daher müssen diese vom Kunden auch separat bezahlt werden. Hierunter fallen in erster Linie die Kosten für die virtuellen Maschinen, die die Datenpipelines ausführen. Allerdings fallen auch Kosten für Netzwerkkomponenten wie VPNs und anderen Azure Ressourcen wie Azure Data Factories oder Key Vaults.
Der Großteil dieser Kosten skaliert über die Nutzung. Das bedeutet, dass sie auftreten, wenn bspw. eine Datenpipeline ausgeführt, Daten abgerufen oder ein PowerBI Report aktualisiert wird.
Den Preis für jede Ressource pro Stunde kannst Du über den Azure Preisrechner unter Preisrechner | Microsoft Azure bestimmen.
- Lizenzen: Für die Ausführung von Datapipelines, dem Abruf von Daten über ein SQL Warehouse und für die Nutzung von Serverless Compute - die nicht über die eigene Azure Subscription abgedeckt werden - erhebt Databricks Lizenzkosten.
Diese Kosten werden immer in Databricks units pro Stunde (DBU/h) angegeben. Hier gestaltet sich die Berechnung in tatsächliche Euro jedoch etwas schwerer, da für unterschiedliche Nutzungen ein unterschiedlicher Preis pro DBU/h verlangt wird.
Wenn man als Kunde z.B. eine Standard DS3v2 Maschine als Entwicklungsmaschine verwenden möchte, verlangt Azure pro Stunde ca. 48 Cent. Für eine Maschine dieses Typs kommen dann pro Stunde noch 0,75 DBU dazu. In unserem Beispiel wären das All-purpose DBUs für ca. 53 Cent pro Stunde. Wir bezahlen also insgesamt ca. 89 Cent pro Stunde für den Betrieb dieses Computers.
Würden wir diesen statt als Entwicklungsmaschine als Job Computer verwenden, würden wie Job Compute DBU nur noch 29 Cent pro Stunde kosten. Ergo würde die Stunde Betrieb in einer Datapipeline nur noch 70 Cent kosten. Insgesamt gibt es zehn verschiedene Arten von DBUs, die alle unterschiedlich bepreist sind:
- All-Purpose: 0,528€/DBU
- Jobs-Compute: 0,288€/DBU
- Jobs-Compute-Light: 0,212€/DBU
- SQL-Compute: 0,212€/DBU
- SQL-Pro-Compute: 0,691€/DBU
- Serverless-SQL: 0,874€/DBU
- Serverless Realtime Inference: 0,081€/DBU
- Modelltraining: 0,749€/DBU
- Interactive Serverless Compute: 0,672€/DBU
- Automated Serverless Compute: 0,240€/DBU
Diese Preise sind aktuell für die Azure Region EU-West im Databricks Premium Tarif während dieser Artikel geschrieben wurde - prüfe aber regelmäßig die Preise unter Azure Databricks - Preise | Microsoft Azure, da sie sich auch ändern können.
Logischerweise skalieren auch diese Preise über die Nutzung. Übrigens: Für die Nutzung von Databricks gibt es keine weiteren Lizenzkosten - keine Entwicklungslizenzen für die Nutzung der Oberfläche o.Ä.
- Speicher: Der letzte Kostentyp ist der tatsächlich verbrauchte Speicherplatz. Anders als die anderen Kostentypen skaliert dieser mit dem Speicherverbrauch und nicht mit der Compute Nutzung.
Diese Kosten werden auch über Azure direkt abgerechnet. Neben dem Speicherverbrauch kommen auch noch geringe Gebühren für Lese- und Schreibvorgänge dazu. Relativ teuer können auch Add-ons wie SFTP Zugang oder Georedundante Speicheroptionen werden. Das kann allerdings auch über den Azure Preisrechner unter Preisrechner | Microsoft Azure vorab berechnet werden.
Kostentransparenz
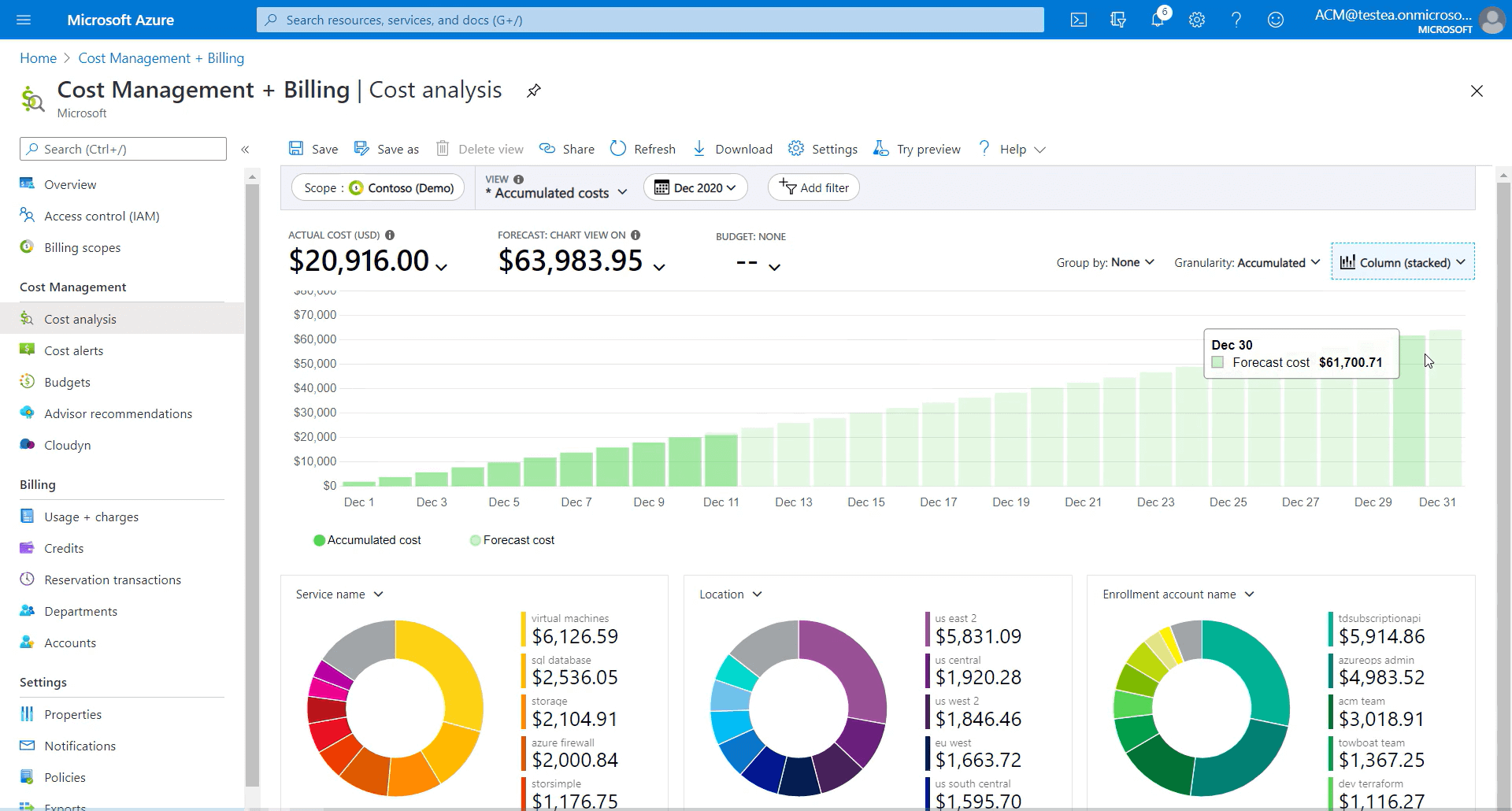
Um unsere Kosten optimieren zu können, brauchen wir erstmal eine Transparenz über das was wir tatsächlich bezahlen. Ein erster Anlaufpunkt ist hierbei das Kostenmanagement in Azure. Hier können tagesaktuell Kosten der verschiedenen Azure Ressourcen, die für Databricks verwendet werden, überwacht werden. Für eine Detailreichere Übersicht bietet sich allerdings die Anbindung der Azure Kostenschnittstelle oder eine Datenvereinnahmung in Databricks selbst an. Damit können dann deutlich umfangreichere Dashboards gebaut werden, um die Kosten und den Verbrauch im Blick zu behalten.
Kostenoptimierung
Es gibt unzählige Möglichkeiten, die Kosten in Azure Databricks zu senken. Die meiner Erfahrung nach effektivste Lösung ist eine genaue Analyse der Anforderungen für jedes Projekt. Nicht jede Datenpipeline muss bspw. im Fünf-Minuten-Takt durchlaufen und nicht jedes Quellsystem muss immer in seinem gesamten Umfang angebunden werden. Erst wenn wir uns über die genauen Anforderungen im Klaren sind, können wir an den Kosten schrauben. Hierbei habe ich einige Tipps vorbereitet - diese sind keinesfalls vollständig, aber können einen ersten Absprungpunkt bieten.
- Job-Compute vs. All-Purpose-Compute: Job Compute Cluster schalten sich im Vergleich zu All-Purpose Clustern direkt nach der Ausführung eines Jobs wieder ab. Dagegen können All-Purpose Computer frühestens nach 10 min. nach der letzten Ausführung automatisch abgeschalten werden. Zusätzlich sind Job-Compute Cluster im Betrieb aufgrund von günstigeren DBU Preisen schlicht günstiger.
Es gibt allerdings auch Fälle in denen ein All-Purpose Compute Cluster günstiger sein kann. Das ist immer dann der Fall, wenn die Ausführungen der Pipelines sehr eng getaktet sind, da bei Job Compute Clustern mehrere Computer parallel hoch und herunterfahren würden.
- Cluster Konfiguration: Bei der Cluster Konfiguration ist es wichtig, eine angemessene Zeit für die automatische Ausschaltung zu konfigurieren und eine möglichst niedrige Konfiguration zu wählen von der aus dann aufskaliert werden kann. Wichtig ist vor allem ca. 50% mehr RAM Speicher einzuplanen, als die größe der tatsächlichen Datensets die verarbeitet werden müssen.
Auch die Aktivierung der Photon Funktion kann trotz höherer DBU Kosten eine gute Möglichkeit sein, Kosten zu sparen, da die Pipeline Ausführungen kürzer sein können.
- Serverless Compute: Ein großes Problem sind häufig die Wartezeiten bei hoch und herunterfahren von Compute Clustern. Diese verlangsamen nicht nur Pipelineausführungen, sondern erzeugen auch Kosten, da der Compute auch für diese Zeiten bezahlt werden muss. Bei serverless Computes fällt diese Zeit fast komplett weg - sie stehen sofort zur Verfügung und werden nur für die Zeit bezahlt in der sie tatsächlich genutzt werden. Dafür sind sie etwas teurer - sie eignen sich also speziell für unplanbare und Datenloads mit kurzen Ausführungszeiten wie SQL Abfragen für Dashboards.
- CDC statt Overwrite: Beim Transformieren von Daten werden häufig Tabellen über CREATS TABLE AS (CTAS) erstellt bzw. überschrieben. Dabei werden faktisch die gesamten Daten neu geladen und die Tabelle überschrieben. Bei großen Datensets kann das sehr lange dauern und teuer werden. Deutlich besser wäre es stattdessen den MERGE Befehl zu verwenden und nur Änderungen zu laden. Das ist in der Entwicklung allerdings etwas aufwändiger, da die Primärschlüssel der Tabellen bekannt sein und eine entsprechende Merge Query gebaut werden muss